分布式 TensorFlow 深度调研
HDFS 支持
TensorFlow 本身已经支持读写 HDFS 上的数据, 所以编写 TensorFlow 应用不必要依赖 Spark 或 YARN 的功能. 读写的数据格式不受限制, 可以是 csv/pickle/TFRecords, 以及其它自定义的格式, 只需要指定相应的读写类. 详情参考官方文档以及 feeding.
GPU 支持
如果需要使用 GPU, 在 Python 编写的应用中, 只需要 with.device() 中传人相应的设备即可, 参考 Using GPUs. 而可用的 GPU 设备需要通过 nvidia-smi 命令获取. 只是在分布式环境下, 需要考虑多个应用共享 GPU 时的调度问题.
Docker 支持
在我们的环境中, 对于 Docker 的使用都是由 YARN 调度的. 如何通过 YARN 调度 Docker, 需要在 NodeManager(NM) 拉起 ApplicationMaster(AM) 和 Container 时, 已经设置好环境变量 yarn.nodemanager.container-executor.class=ContainerClassName 和 yarn.nodemanager.container-executor.image-name=AccessibleImageName. 通常是由提交客户端接收命令行参数, 提取 AM 需要的环境变量传递给某个 NM , 由该 NM 拉起 Docker AM. 同时把 Container 需要的环境变量传递给 AM, 再由 AM 把这些环境信息分发到申请 NM 节点, 再启动 YARN Docker Container. 详情参考官方文档. 由于机器环境原因, 目前我没有成功运行过.
在 Docker 中运行 TensorFlow 需要注意以下几个问题:
- 集群中的各个 NM 节点运行着 Docker daemon.
- NM 节点可以访问相关的 image.
- YARN 的配置文件配备了 Docker 运行属性. 参考 Cluster Configuration.
- 如果要启动 GPU 容器, 需要使用
nvidia-docker. 参考 Installing with Docker.
任务管理
- 任务提交, 通过客户端直接向集群提交任务
- TensorFlowOnYarn 分两步提交
- ydl-tf –num_ps
--num_worker - python path/to/app.py –ps_hosts=
--worker_host= --job_name --task_index=
- ydl-tf –num_ps
- TensorFlowOnSpark 和一般的 Spark 任务提交方式保持一致
- TensorFlowOnYarn 分两步提交
- 日志管理, 如果是运行在 YARN 上, 都可以通过
yarn logs -applicationId <AppID>获取运行日志.
代码移植
- 移植到 TensorFlowOnYarn
- 目前项目中使用的方法是通过
ydl-tf拉起集群后, 再在客户端上拉起一个或多个 TensorFlow server. 这个方法不需要对原有代码进行修改.
- 目前项目中使用的方法是通过
- 移植到 TensorFlowOnSpark, 具体细节可以参考项目中的例子
- 使用
TFCluster替代tf.app.run拉起集群 - 使用
TFNode.start_cluster_server替代tf.train.Server启动 TensorFlow server.
- 使用
运行环境
- 异构服务器, 源代码中并没有处理不同类型的服务器, TensorFlowOnSpark 与 TensorFlowOnYarn 目前只能运行在同种服务器上, 通过标签方式来控制.
- 现有集群软件安装, 在使用过程中由于环境问题的困扰, 建议采用 Docker, 或 virtualenv.
- 待确认问题: 可以在 Docker 容器中查询硬件信息吗?
分布式 TensorFlow 中的概念
通过 Distributed TensorFlow, 理解 TensorFlow 中的 Cluster/Job/Task 的关系与用法, in-graph replication 和 between-graph replication 的区别, 以及异步训练和同步训练.
基本概念
- Task. 对应特定的 TensorFlow Server, 一般来讲是一个单进程实体, Python 代码中体现为
tf.device("/job:xx/task:xx"). 从程序的使用上看, 一个 Task 属于特定的 Job, 并由该 Job 中的任务列表的索引号标识. - Job. 由一组服务与共同目标的 Tasks 构成. 例如, PS(parameter server) Job 用于存储和共享
tf.Variable, worker Job 管理一组计算密集型的 Task 节点. Job 中的 Task 一般会运行在不同的服务器上. - Cluster. 所有参与计算的 Task 构成 Cluster, 使用 tf.train.ClusterSpec 描述, 其中的每个独立资源的描述形式为
hostname:port, 这就表明一台服务器上其实是可以运行多个 Task 的. - TensorFlow server. 运行
tf.train.Server的进程实体, 属于 Cluster 中的成员, 并提供 master service 和 worker service. - Master service. 为分布式 devices 提供远程访问的 RPC 服务. 主要负责协调一到多个 worker service 间的协调工作. 所有的 TensorFlow servers 都要实现 master service.
- Worker service. An RPC service that executes parts of a TensorFlow graph using its local devices. 所有的 TensorFlow servers 都要实现 master service.
- Client. 构建 TensorFlow graph, 启动与 Cluster 交互的
tensorflow::Session. Client 与 TensorFlow servers 的关系可以是一对多(见 Replicated traing), 或多对多.
Replicated training
在大数据量场景下. 一般会考虑采用并行方式, 加快训练速度. 解决办法是把数据分解成小批数据, 把每一批数据分别提供不同的 Task 进行处理, 并更新托管在 PS Job 中某个具体的 Task 中的共享参数. 一般来讲, 所有的 Task 运行在不同的服务器上. TensorFlow 提供了几种方法, 可以独立使用或组合使用来完成并行训练.
- In-graph replication. 在这种方法里, 客户端构建一个单独的
tf.Graph, 它包含一组关联到/job:ps上的tf.Variable节点(即参数), 并把模型中计算密集型的部分复制多个副本, 分别交给不同的任务/job:worker. 这个方法使用场景不多, 可以用在含多个 GPU 的服务器上. 主要特定是只构建一个tf.Graph. - Between-graph replication. 在这个方法里, 会为每个
/job:workerTask 创建一个独立的 Client, 通常与 worker task 共享同一个进程实体. 这些客户端分别构建自己的 similar graph(不是必须相同), 并通过tf.train.replica_device_setter将参数关联到/job:ps, 并与相应的 Task 建立映射关系. 客户端还会把模型中计算密集型的一份副本关联到本地/job:workertask 中. 这里面的每一个 worker task 可能处理同一份数据, 也可能处理从同一份数据中的分解的小批数据. 与 In-graph replication 的区别是会为每个/job:workerTask 创建一个独立tf.Graph. - Asynchronous training. 在这个方法里, graph 中的每个 replica 独立执行, 彼此不需要独立. 它与上面两种方式可以共用.
- Synchronous training. 与 Asynchronous training 相反, replica 之间需要协作. 也可以与 In-graph/Between-graph replication 共用.
参考 the difference between in-graph replication and between-graph replication. 解答疑问:既然我们有多个 worker, 我们不是应该把模型的密集型计算部分复制多个副本吗?
一般来说, 每一个 worker 都有一个密集型计算模型的独立 graph. worker i 的 graph 不包含 worker j (假定 i ≠ j) 的 graph 中的 nodes. 例外情况, 在分布式训练中使用 Between-graph replication, 或在 In-graph replicaiton 场景下每个 worker 使用多个 GPU. 在上面这两者情况中, 每个 worker 的 graph 一般就会把模型中计算密集型部分复制出 N 个副本, 其中 N 是 worker 所使用的 GPU 数量(补充: 在 Between-graph 中,为 worker 的数量).
TensorFlowOnSpark 项目现状
软件架构
- TensorFlowOnSpark 架构
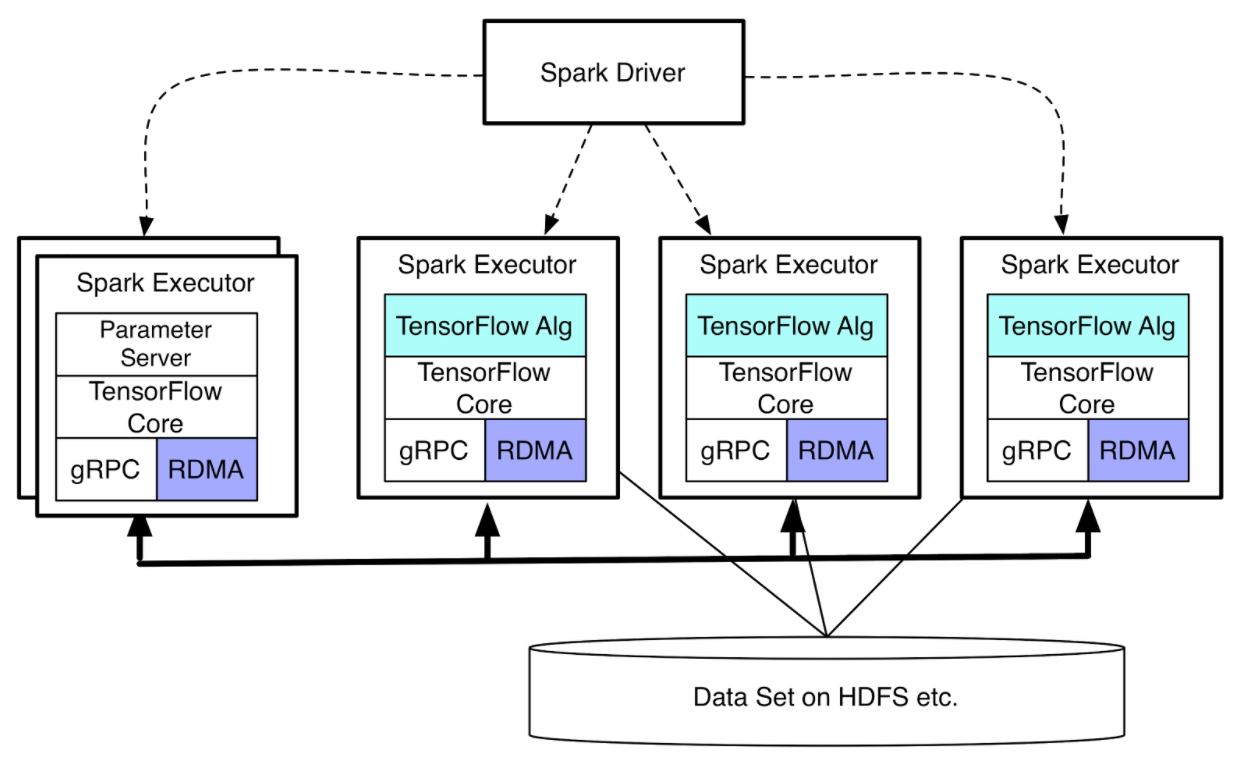
- TensorFlow Cluster 启动过程和 ClusterSpec 构建流程
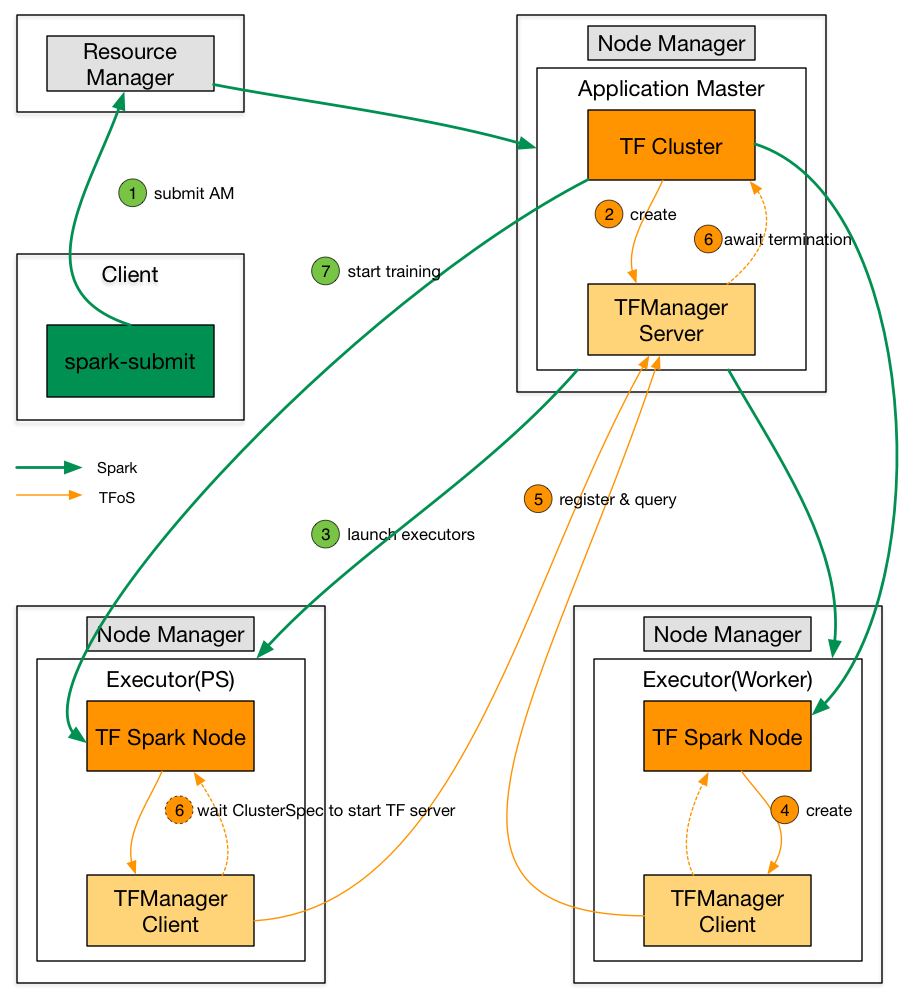
特性
- 支持多 Parameter Server 与多个 Worker.
- Executor 间的控制通信采用 TFManager, 可以考虑采用 Spark 自身特性进行, 如 Broadcast/Accumulator.
- 支持 feed_dict 与 QueueRunners 的数据分发方式.
- 支持 TensorBoard.
- 提交方法与 Spark 应用一致, 不过用户程序需要做少量的修改.
TensorFlowOnYarn 项目现状
软件架构
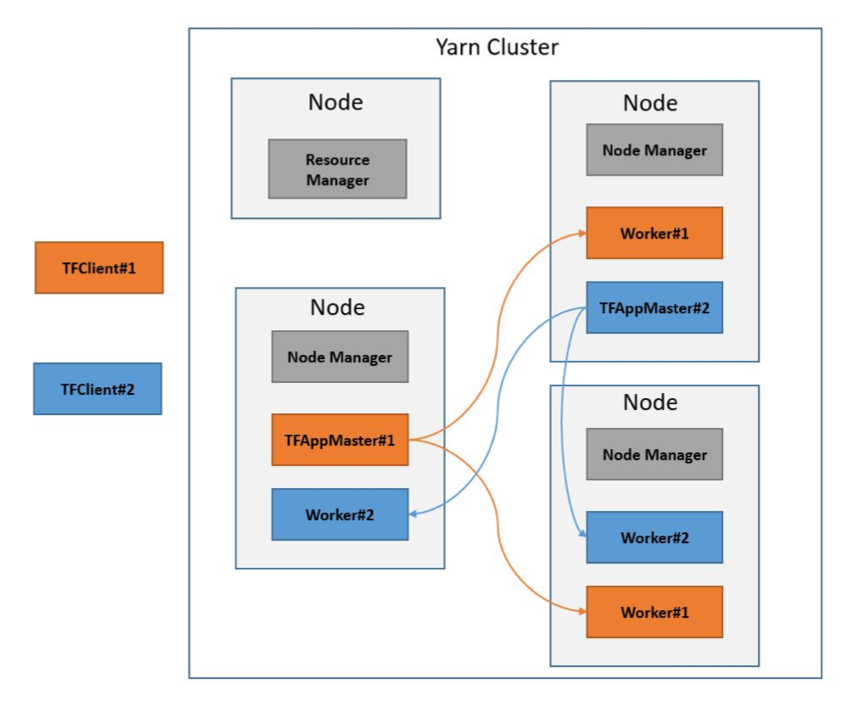
- 在 YARN 集群中各个组件布局
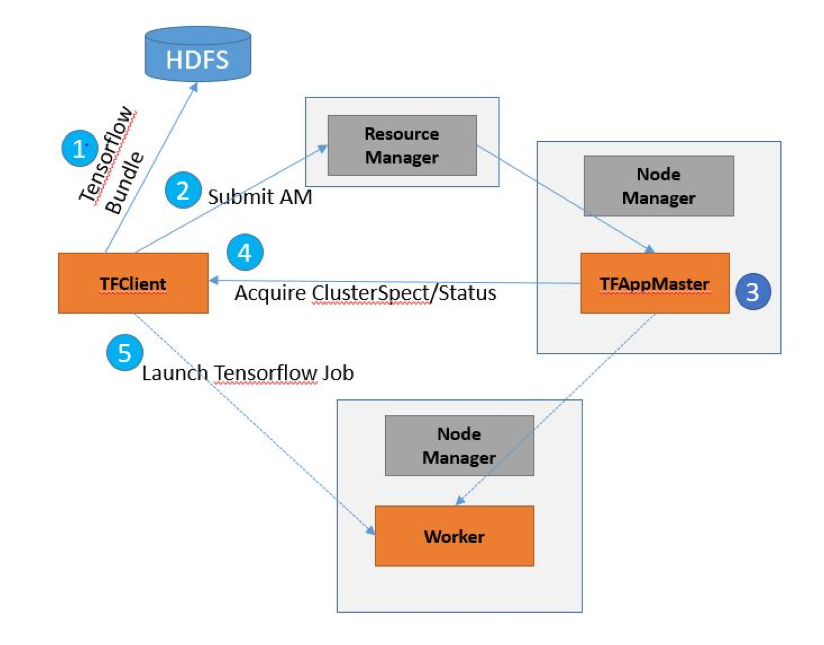
- TensorFlowOnYarn Client 的启动流程
- TensorFlowOnYarn Application Master 的工作流程
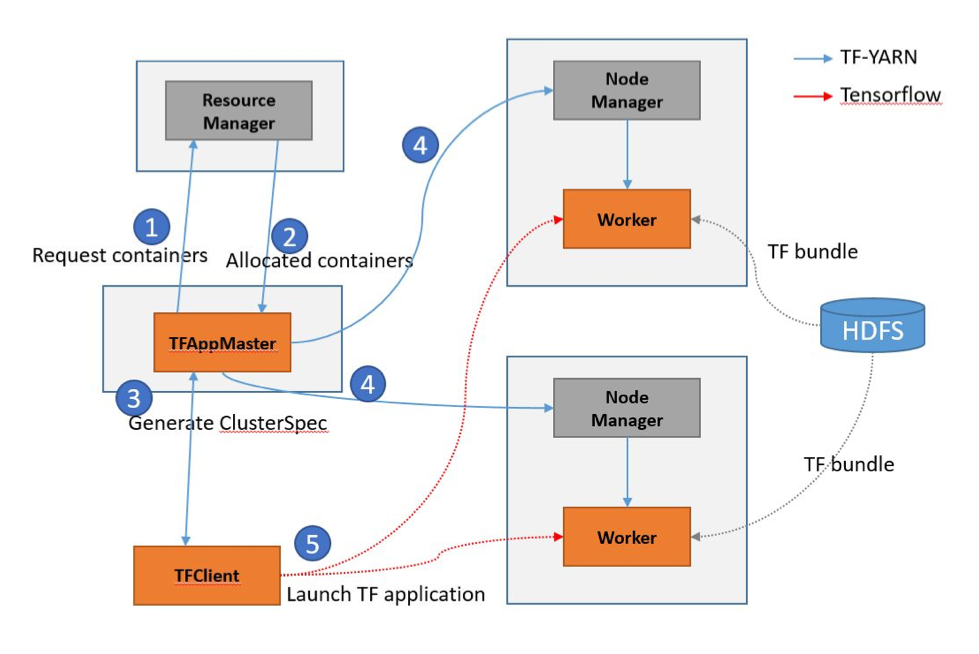
- 详细设计参考设计文档.
特性
- 程序通过 native 方法在各个 Container 中启动 TensorFlow Server, 客户端程序通过给定的 ClusterSpec 与服务建立通信.
- 支持多 Parameter Server 与多个 Worker.
- Executor 间的控制通信采用定制的 grpc 方案, 目前仅用于获取 ClusterSpec 信息.
- 暫不支持 TensorBoard, 參考 TensorFlowOnSpark, 也很容易支持 TensorBoard.
- 提交方法与 Yarn 应用不太相同, 需要单独提交训练任务. 不过可以改造, 使其与 Yarn 的一般使用方法保持一致. 需要在 YARN Container 中调用 Python, 还有如何对内存与 CPU 的资源进行控制.
总结
- 两者的架构与内部实现细节区别不大, 不过 Spark 可以非常方便的启动 Executor 以及 Spark 提供的基础功能, TensorFlowOnSpark 的改造工作相对较少.
- 在 TensorFlow Serving 方面, 两者都没有提供支持, 不过在 Spark 上进行改造, 倒是可以考虑用 Spark Streaming 提供支持.
- TensorFlow 本身提供了 HDFS 的支持. 在这方面, 两个框架都不需要考虑. 倒是任务失败再恢复是问题的核心.